Large engineering organizations run production systems that span microservices, managed databases, message queues, CDNs, edge functions, Kubernetes clusters, and third-party APIs. Each layer generates logs, metrics, traces, spans, profiles, real-user monitoring data, and synthetic check results at volumes that no individual or team can monitor manually. Without a platform that brings those signals together with shared context, incident investigations become a cross-tool puzzle that costs hours instead of minutes.
Choosing from the available enterprise observability platforms is not straightforward. Most vendors claim unified visibility, but they differ significantly on pricing models, data retention architecture, OpenTelemetry support, AI-assisted investigation capabilities, governance features, and deployment flexibility. A platform that works for a small engineering team often fails at the compliance, cardinality, and cost requirements of a large organization running hundreds of services.
This guide compares the 10 best enterprise observability platforms in 2026 by features, pricing, deployment model, pros, cons, and best-fit use case. It is written for engineering leaders, platform teams, and SREs who are evaluating options and need a buyer-aligned observability platform comparison rather than a vendor feature list.
What is an enterprise observability platform?
An enterprise observability platform is software that collects, correlates, and analyzes logs, metrics, traces, events, service maps, user experience data, and infrastructure telemetry across large production environments. The goal is not just to store data: it is to give engineering teams the context they need to understand system behavior, investigate incidents, detect anomalies, and control costs as the system scales.
Enterprise-grade platforms go beyond basic monitoring. They handle multi-tenant environments, governance controls, high-cardinality telemetry, long retention requirements, compliance needs, and integration with organizational workflows like incident management and on-call rotation.
What enterprise observability platforms actually do
At a minimum, a production-ready platform for enterprise teams handles:
- Signal collection: Ingesting logs, metrics, traces, events, RUM data, synthetic results, and infrastructure telemetry from distributed sources at scale
- Correlation: Linking a slow trace to the related log lines, the metric that spiked, and the deployment that preceded the incident
- Service topology: Auto-discovering or building service maps that show dependencies and blast radius across environments
- Alerting and anomaly detection: Surfacing problems through threshold alerts, statistical anomaly detection, or AI-assisted grouping
- Dashboards and reporting: Visualizing system health, SLOs, error budgets, and trends for engineering and leadership
- Retention and cost management: Tiering data across hot, warm, and cold storage while keeping it queryable throughout the retention period
- Governance: Role-based access controls, SSO, audit logging, data residency controls, and multi-tenancy for enterprise compliance requirements
Enterprise observability platforms vs observability tools
The difference is scope and depth:
- Monitoring tools show what is happening: a metric threshold exceeded, a service is down.
- Observability tools typically solve one layer: a log aggregation system, a metrics store, a tracing backend, a dashboarding layer, or an APM agent. Many teams stitch several of these together.
- Enterprise observability platforms unify multiple telemetry signals, governance controls, AI-assisted investigation, cost management, and enterprise deployment needs into a coherent workflow. The value is in the correlation across layers, not in any individual layer alone.
- Observability platforms help teams understand why it is happening and where to act, by connecting the symptom to the upstream cause, the related change, and the affected services.
This distinction matters for buyers evaluating full-stack observability platforms. A team at this stage is not looking for better dashboards alone. They are looking for a platform that can replace or consolidate a fragmented stack of logging, metrics, APM, and alerting tools under one coherent data model and investigation workflow.
What to look for in enterprise observability platforms
Use this as the evaluation framework when building your shortlist.
- Core telemetry coverage: Confirm that the platform handles all the signal types your team actually uses: logs, metrics, traces, events, RUM, synthetics, profiling, and infrastructure data. Some platforms excel at one or two signals but require bolt-on products or third-party integrations for the rest. The more signals that share a data model and investigation workflow, the less context-switching happens during incidents.
- OpenTelemetry support: OpenTelemetry is now the industry standard for telemetry collection. A platform that accepts OTLP natively, works with standard OTel collectors and processors, and stores data in vendor-neutral formats keeps your telemetry pipeline portable. Platforms that require proprietary agents or formats increase migration risk and reduce flexibility as your architecture evolves.
- Correlation and root cause analysis: A platform that stores logs separately from traces and metrics with no shared context is not much better than three separate tools. Look for platforms that link alert events to the related trace, the related log lines, the deployment that preceded the incident, and the service dependency graph. The workflow from alert to root cause is where observability platforms differ most in practice.
- AI-assisted investigation: AI capabilities in observability platforms range from useful to superficial. What matters is whether the AI reduces time to root cause: grouping related alerts, summarizing incident timelines with links to evidence, suggesting next steps that engineers can actually verify, and forecasting saturation or capacity risks before they become incidents. AI that narrates without linking to queryable evidence is not useful during an active outage.
- Cost control: Observability pricing at enterprise scale can surprise teams that model only the base per-GB ingestion rate. Storage architecture, indexing overhead, cardinality handling, retention tiers, and query costs all compound. Platforms built on object storage with columnar formats tend to be significantly cheaper at high retention volumes than index-heavy platforms. The true cost of observability is almost always architecture-driven, not headline-price-driven.
- Governance and compliance: Enterprise environments need RBAC granular enough to scope team access by service or environment, SSO with OIDC or SAML, audit logging for regulatory requirements, data residency options for jurisdictional compliance, multi-tenant controls, and the ability to export or delete data on demand. These are not optional for regulated industries.
- Deployment flexibility: SaaS is the fastest path to value. Self-hosted is the right choice when data residency, compliance, or cost control at scale requires infrastructure ownership. Bring-your-own-cloud (BYOC) models give enterprise teams the managed experience without sending data to the vendor's infrastructure. Evaluate whether the platform genuinely supports the deployment model your organization requires, not just the one it prefers to sell.
Best enterprise observability platforms at a glance
| Platform | Best for | Deployment | OpenTelemetry support | AI capabilities | Pricing model | Key limitation |
|---|---|---|---|---|---|---|
| Parseable | Cost-efficient unified telemetry at scale | Self-hosted, BYOC, Cloud | Native OTLP | Investigation, anomaly detection, forecasting | $0.39/GB; Enterprise from $15K/year | Smaller ecosystem than Datadog or Dynatrace |
| Datadog | All-in-one SaaS observability | SaaS | Supported | Bits AI, LLM Observability | Modular per product | Pricing compounds significantly at scale |
| Dynatrace | Automated root cause in complex enterprises | SaaS, Managed | Supported | Davis AI, automated anomaly detection | Custom enterprise | Premium pricing; deep lock-in |
| New Relic | Full-stack visibility with usage-based pricing | SaaS | Supported | New Relic AI (Grok) | 100 GB free, then $0.30/GB | Proprietary NRQL; SaaS only |
| Splunk | Enterprise log analytics and security depth | SaaS, Self-hosted | Supported | AI-driven alerting | Custom / ingest-based | High cost; SPL learning curve |
| Grafana Cloud | Open-source-aligned observability | Self-hosted, Cloud | Native OTLP | Limited native AI | Usage-based | Self-hosting is operationally intensive |
| Elastic Observability | Search-centric observability for ELK teams | Self-hosted, Cloud | Supported | ML anomaly detection | Open source / Elastic Cloud subscription | Index overhead; operational complexity at scale |
| Chronosphere | Metrics-heavy Kubernetes and high-cardinality | SaaS | Supported | Cost analytics | Custom enterprise | Metrics-first; log and trace maturity still growing |
| Coralogix | Streaming analytics and telemetry cost control | SaaS, Self-hosted | Supported | AI incident assistant | Usage-based | Cross-signal correlation less seamless than APM-first tools |
| Honeycomb | High-cardinality distributed tracing and debugging | SaaS | Supported | Query Assistant | Free tier; Team from $100/month | Not a full-stack platform |
Try Parseable for free and test it against your own workloads.
Top 10 enterprise observability platforms in 2026
1. Parseable: Best enterprise observability platform for cost-efficient unified telemetry
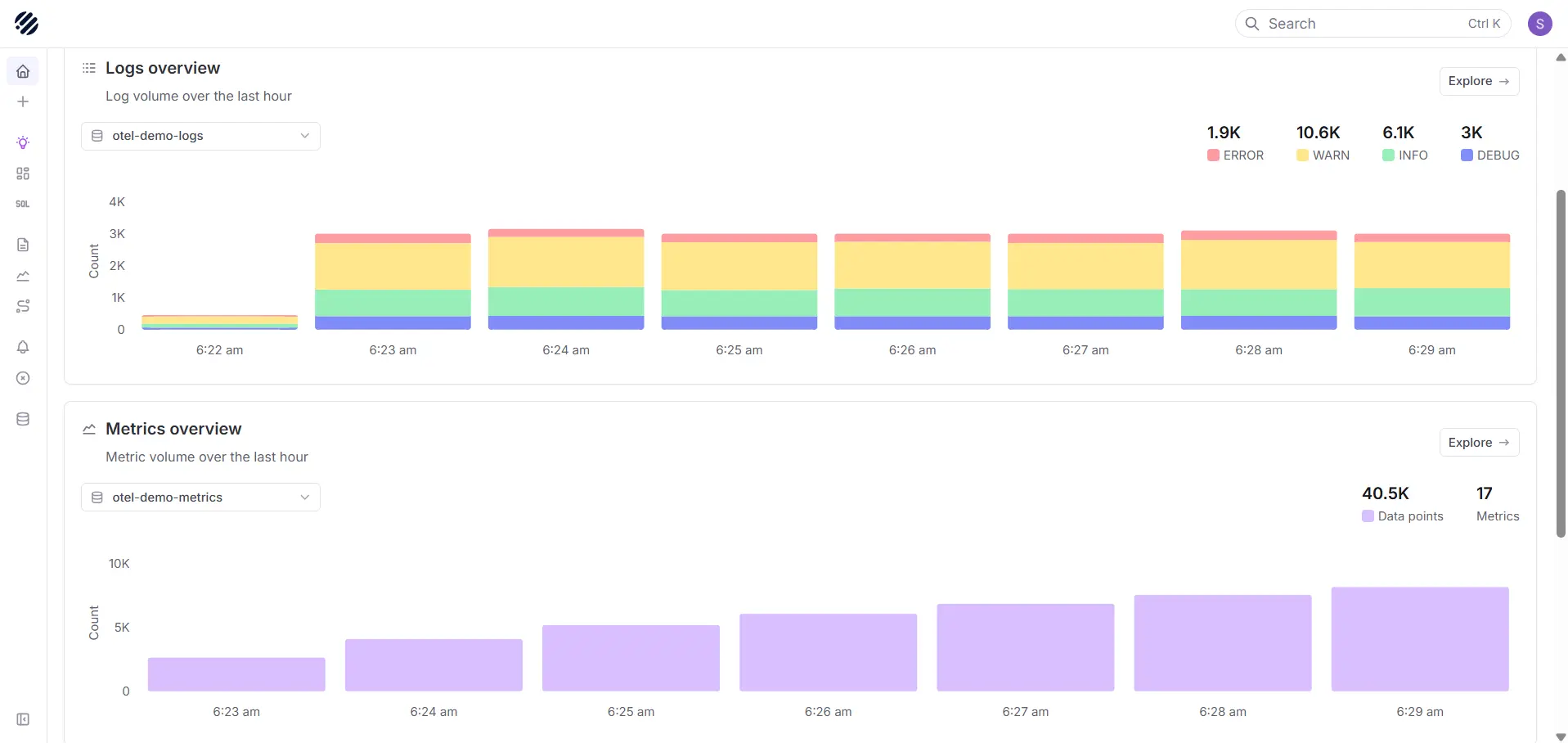
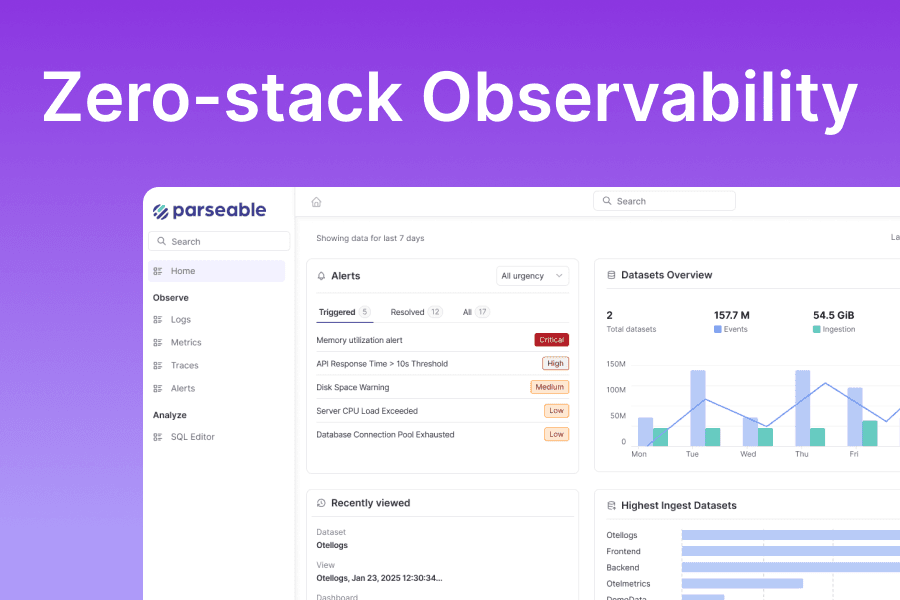
Parseable is a unified observability platform built for teams that need logs, metrics, and traces at scale without the cost and lock-in that come with legacy observability pricing. Its architecture runs on object storage backends such as S3, uses a columnar data format (Apache Parquet), and exposes a SQL-first query model that keeps both query speed and retention cost under control as ingest volumes grow.
Where most cloud observability platforms require teams to choose between data completeness and affordability, Parseable's object-storage design allows teams to keep more data for longer at a lower total cost. That changes the economics of observability for organizations that have historically discarded high-volume telemetry because indexing and retention were too expensive.
Parseable supports OpenTelemetry-native ingestion, which means it integrates into existing OTel collector pipelines without proprietary agents or format conversions. Its AI-assisted investigation capabilities help teams move from an alert to a root-cause hypothesis without manually correlating across dashboards. For enterprises that need deployment flexibility, Parseable is available as a self-hosted platform, Parseable Cloud, or in BYOC configurations where teams keep data in their own storage infrastructure.
Key features
- Unified logs, metrics, and traces: All core telemetry signals in one platform with shared context for cross-signal incident investigation
- OpenTelemetry-native ingestion: OTLP/HTTP endpoints and collector-compatible pipelines with vendor-neutral schemas
- SQL-first exploration: Query logs, metrics, and traces using SQL, removing the proprietary query language barrier for engineering and data teams
- Object-storage-first architecture: S3-compatible backends with Apache Parquet columnar storage reduce long-term retention costs compared to indexing-heavy platforms
- AI-assisted investigation: Anomaly detection, incident summaries linked to specific queries and traces, next-step suggestions, and saturation forecasting
- Dashboards and alerting: Built-in visualization and alert workflows with direct drill-down into raw telemetry
- RBAC, SSO, and audit logging: Enterprise governance controls for access management and compliance
- Deployment flexibility: Self-hosted, Parseable Cloud, and BYOC for teams with data control and compliance requirements
Pricing
- Pro: $0.39/GB ingested, 365-day retention, 14-day free trial
- Enterprise: From $15,000/year, includes BYOC and self-hosted deployment options, dedicated support, and enterprise governance features
- Self-hosted: Cost depends on the team's own infrastructure and object storage expenses
Pros
- Cost-efficient architecture for high-volume telemetry and long-retention requirements
- OpenTelemetry-native and portable: no proprietary agents or vendor-specific schemas required
- SQL-first querying removes the learning curve of proprietary query languages
- Object-storage economics make long retention practical without moving data to unqueryable cold archives
- AI for anomaly detection, investigation summaries with evidence links, and capacity forecasting
- Flexible deployment including self-hosted, cloud, and BYOC for compliance-driven environments
- Strong fit for teams replacing fragmented logging, metrics, and APM stacks with fewer moving parts
Cons
- Some enterprise capabilities such as BYOC and dedicated support require the Enterprise plan
- Teams migrating from incumbent platforms may need to rebuild existing dashboards, alert rules, and runbooks
Try Parseable, the enterprise-grade unified observability platform
2. Datadog: Leading SaaS observability adoption
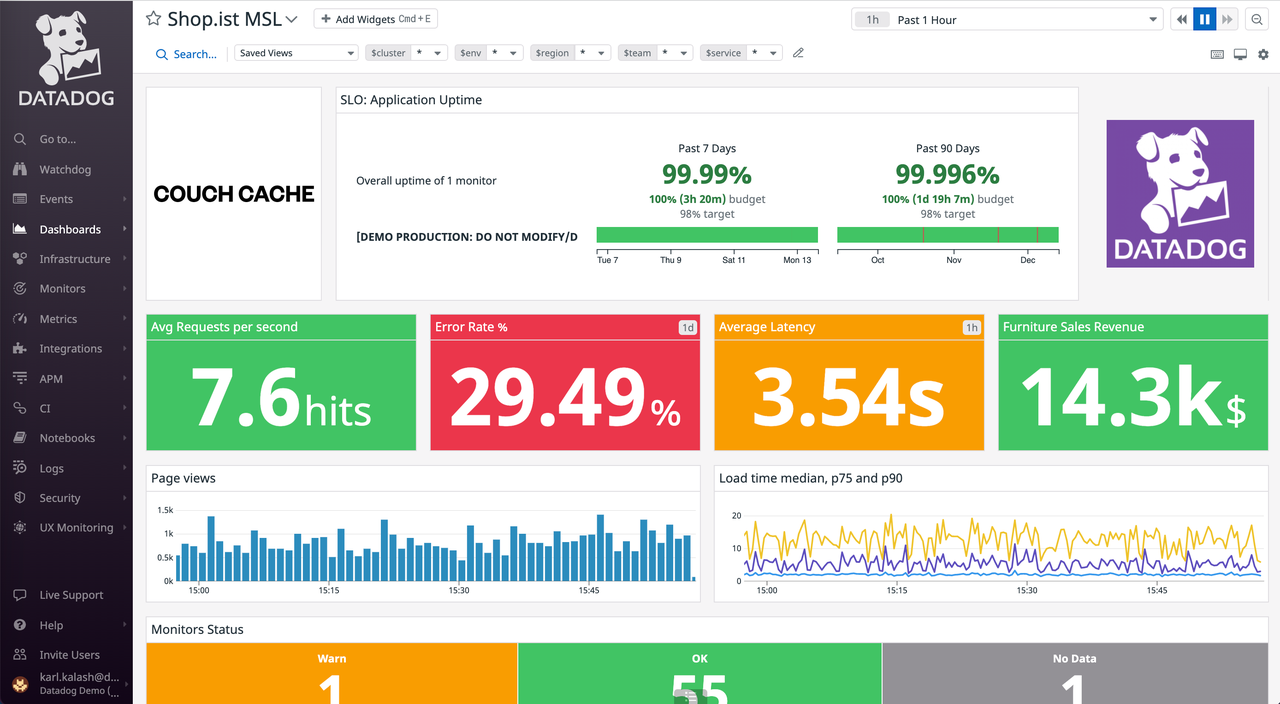
Datadog is the most widely adopted SaaS observability platform for teams that want infrastructure monitoring, APM, logs, RUM, synthetics, security, CI visibility, and incident management in one place. Its integration catalog covers over 600 technologies, and its onboarding experience is built to minimize the time from signup to working dashboards.
For teams already invested in the Datadog ecosystem, adding observability signals is incremental rather than disruptive. Datadog Bits AI can summarize incidents, correlate anomalies across signals, and suggest remediation steps in natural language. The LLM Observability module tracks token usage, latency, and quality metrics for AI-powered production applications, which makes Datadog a strong choice for organizations building AI-intensive services alongside traditional infrastructure.
The primary constraint is cost. Datadog's modular pricing model compounds as teams add products, increase ingestion, index more spans, retain data longer, and instrument more hosts. Teams operating at high log volumes or with many custom metrics often need aggressive sampling, retention tier management, and exclusion filters to keep spend manageable.
Key features
- Infrastructure monitoring and APM: Host-level metrics, container monitoring, distributed tracing, and service performance analysis
- Log management: Live search, log pipelines, parsing, tiered storage, and log-to-trace correlation
- RUM, synthetics, and browser monitoring: End-to-end frontend and user experience observability
- Bits AI: Incident summarization, anomaly correlation, and remediation suggestions across the full platform
- LLM Observability: Token usage tracking, latency analysis, and quality monitoring for AI applications in production
- 600+ integrations: Out-of-the-box coverage for cloud providers, databases, frameworks, and services
Pricing
Datadog uses modular, product-based pricing. Infrastructure monitoring starts at approximately $15 per host per month. Log ingestion starts at $0.10/GB with additional costs for indexing, retention, and rehydration. APM pricing depends on ingested spans and hosts. Custom metrics, synthetics, RUM, and security products are each priced separately. Total spend at high scale can be significantly higher than the sum of individual module rates. See Datadog's pricing page for current rates.
Pros
- Broadest integration ecosystem of any SaaS observability platform
- All signals in one platform: logs, metrics, APM, traces, RUM, synthetics, security, and AI observability
- Bits AI provides practical incident investigation support across all signals
- Mature dashboards, alerting, and notification routing with reliable uptime
Cons
- Pricing compounds quickly across ingestion, indexing, retention, APM, custom metrics, and add-on modules
- Vendor lock-in is substantial: dashboards, alerts, and integrations are difficult to migrate away from
- Not cost-efficient for high-volume log retention without aggressive use of tiering and exclusion filters
- SaaS-only; limited options for teams with strict data residency or on-premises requirements
3. Dynatrace
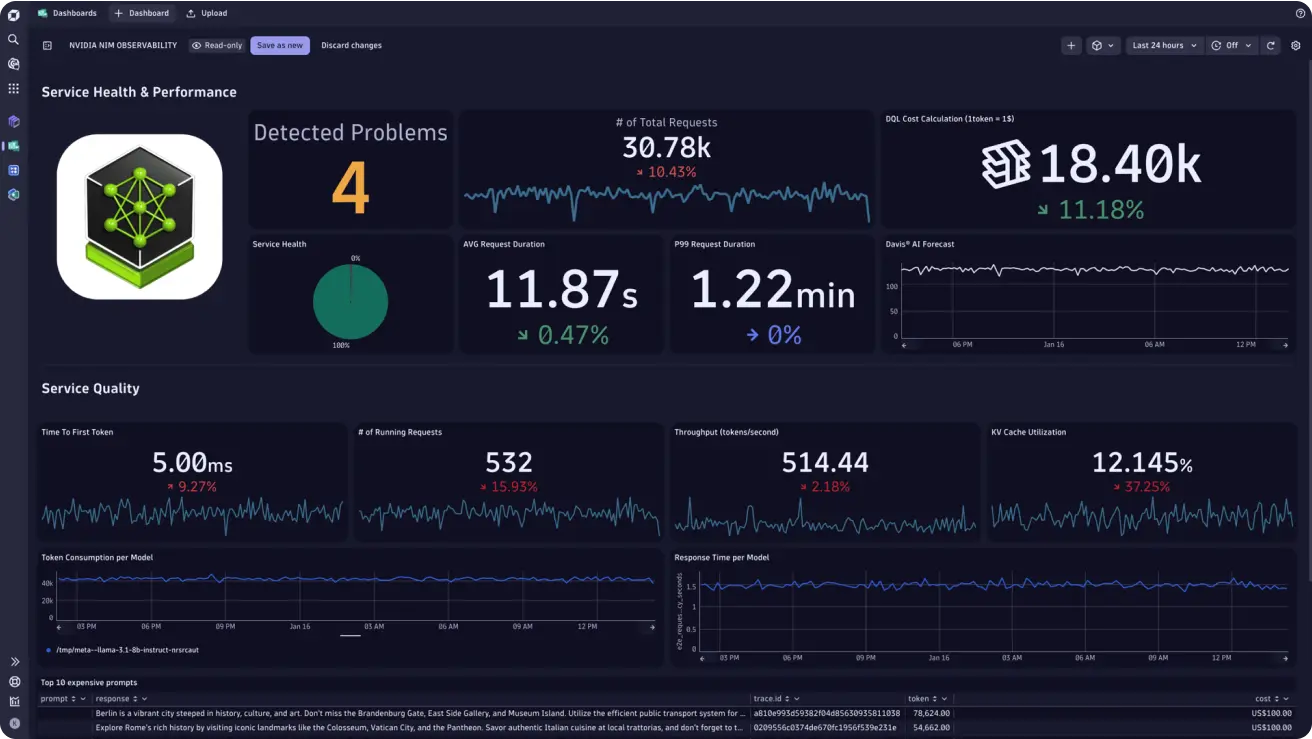
Dynatrace is a full-stack observability platform built for large enterprises that operate complex, heterogeneous environments including cloud-native services, legacy systems, mainframes, SAP and Oracle ERP, and hybrid infrastructure. Its strongest differentiators are automated topology discovery, AI-assisted root cause analysis, and APM depth that goes beyond what most observability platforms offer.
The Davis AI engine is at the core of Dynatrace's investigation workflow. It auto-discovers service dependencies through Smartscape, correlates events across layers in real time, and surfaces ranked probable root causes rather than raw alert noise. For enterprises where incident investigation time is measured against SLA penalties, this automated analysis can meaningfully reduce mean time to resolution.
The Grail analytics engine handles petabyte-scale queries with subsecond response times across logs, metrics, traces, events, and business data in a unified schema. OneAgent auto-instruments code, OS, network, and processes with minimal configuration, which reduces instrumentation overhead for large teams managing dozens of services.
Key features
- OneAgent auto-instrumentation: Zero-config instrumentation across application code, OS, network, processes, and containers
- Smartscape topology mapping: Real-time auto-discovery of service dependencies, infrastructure relationships, and blast-radius analysis
- Grail analytics engine: Unified data lakehouse for logs, metrics, traces, events, and business data with petabyte-scale query performance
- Davis AI: Automated root cause analysis, anomaly detection, and ranked incident correlation across the full topology
- RUM and session replay: Full user journey analysis and session replay for frontend and mobile applications
- Business analytics: Connecting observability signals to revenue impact, conversion metrics, and SLA performance
Pricing
Dynatrace uses custom enterprise pricing based on modules, hosts, DEM units, and ingest volume. Pricing requires direct engagement with Dynatrace sales. It is typically among the higher-cost options on this list, which is justifiable for enterprises where the automation depth delivers measurable reductions in MTTR.
Pros
- Best-in-class automated topology discovery and AI-driven root cause analysis
- Grail engine handles petabyte-scale unified telemetry with fast query performance
- OneAgent reduces instrumentation overhead for large, heterogeneous environments
- Strong support for legacy systems, SAP, mainframe, and hybrid cloud alongside modern Kubernetes
Cons
- Premium pricing that is difficult to justify for smaller or simpler cloud-native environments
- Deep vendor lock-in through OneAgent and proprietary data models
- Full value requires Dynatrace's proprietary agent; OTel support exists but is secondary
- Over-featured for teams that only need cloud-native observability without legacy system coverage
- Requires Dynatrace expertise to fully configure and derive value from
Thinking of implementing Dynatrace for your enterprise's observability need? Try Parseable before starting the POC.
4. New Relic
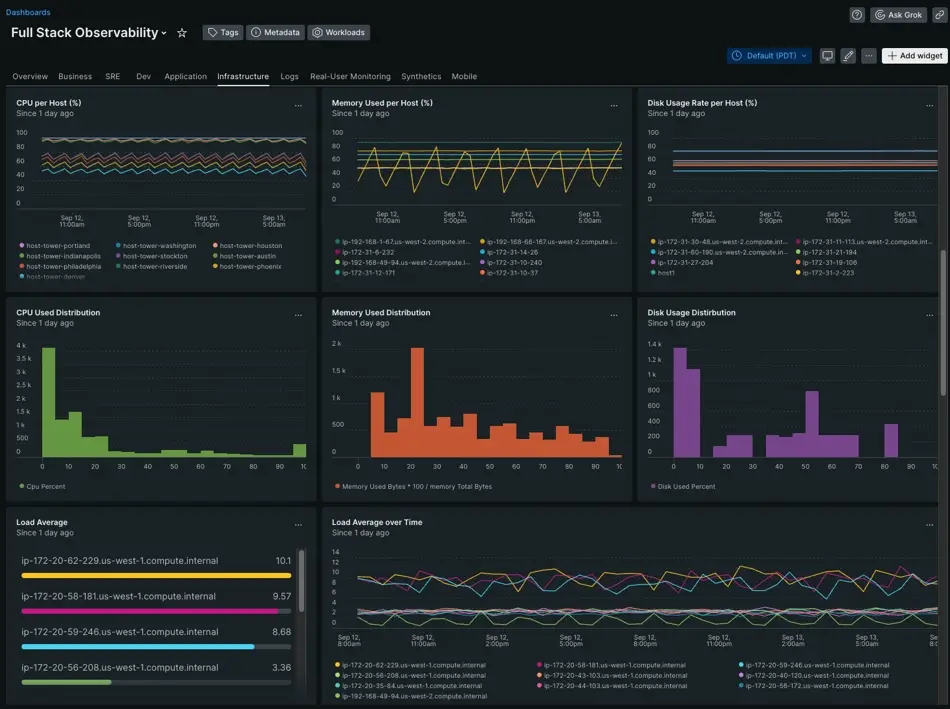
New Relic is a full-stack observability platform that brings APM, infrastructure monitoring, logs, distributed tracing, browser RUM, mobile monitoring, and synthetic checks into a single data model (NRDB). For enterprises that want broad signal coverage with a transparent, consumption-based pricing model and a generous free tier, New Relic is a practical starting point.
New Relic AI (Grok) provides natural language query assistance and can answer observability questions, suggest NRQL optimizations, and summarize system health across connected signals. The platform's instrumentation wizards support over 10 programming languages, serverless environments, and container workloads, which reduces the time to instrument a new service from scratch.
Key features
- APM and distributed tracing: Code-level performance monitoring with distributed trace correlation across services
- Infrastructure and Kubernetes monitoring: Host metrics, container monitoring, and Kubernetes cluster health
- Log management with NRQL: Centralized log search and analysis correlated with traces and metrics using NRQL
- New Relic AI (Grok): Natural language query assistance, NRQL generation, and system health summaries
- Unified data model (NRDB): All telemetry types in a single queryable store for consistent cross-signal analysis
Pricing
New Relic includes 100 GB of data ingestion per month for free across all telemetry types. Beyond the free tier, pricing is $0.30/GB ingested. Full-platform users receive access to all capabilities.
Pros
- 100 GB/month free tier makes evaluation and onboarding accessible without upfront cost
- Broad full-stack coverage across APM, infrastructure, logs, traces, RUM, and synthetics
- Transparent, usage-based pricing that is more predictable than host-based or seat-based models
- NRDB unified data model supports consistent cross-signal queries within the platform
- Strong instrumentation support for diverse language and runtime environments
Cons
- NRQL is a proprietary query language with a learning curve compared to SQL or PromQL
- Cost increases significantly at high ingest volumes beyond the free tier
- Less depth on niche capabilities such as eBPF profiling, mainframe monitoring, or network flow analysis
- Vendor lock-in increases as dashboards, alerts, and runbooks are standardized on NRQL
- SaaS-only; no self-hosted deployment option
5. Splunk Observability Cloud: Best for enterprise observability with security and log analytics depth
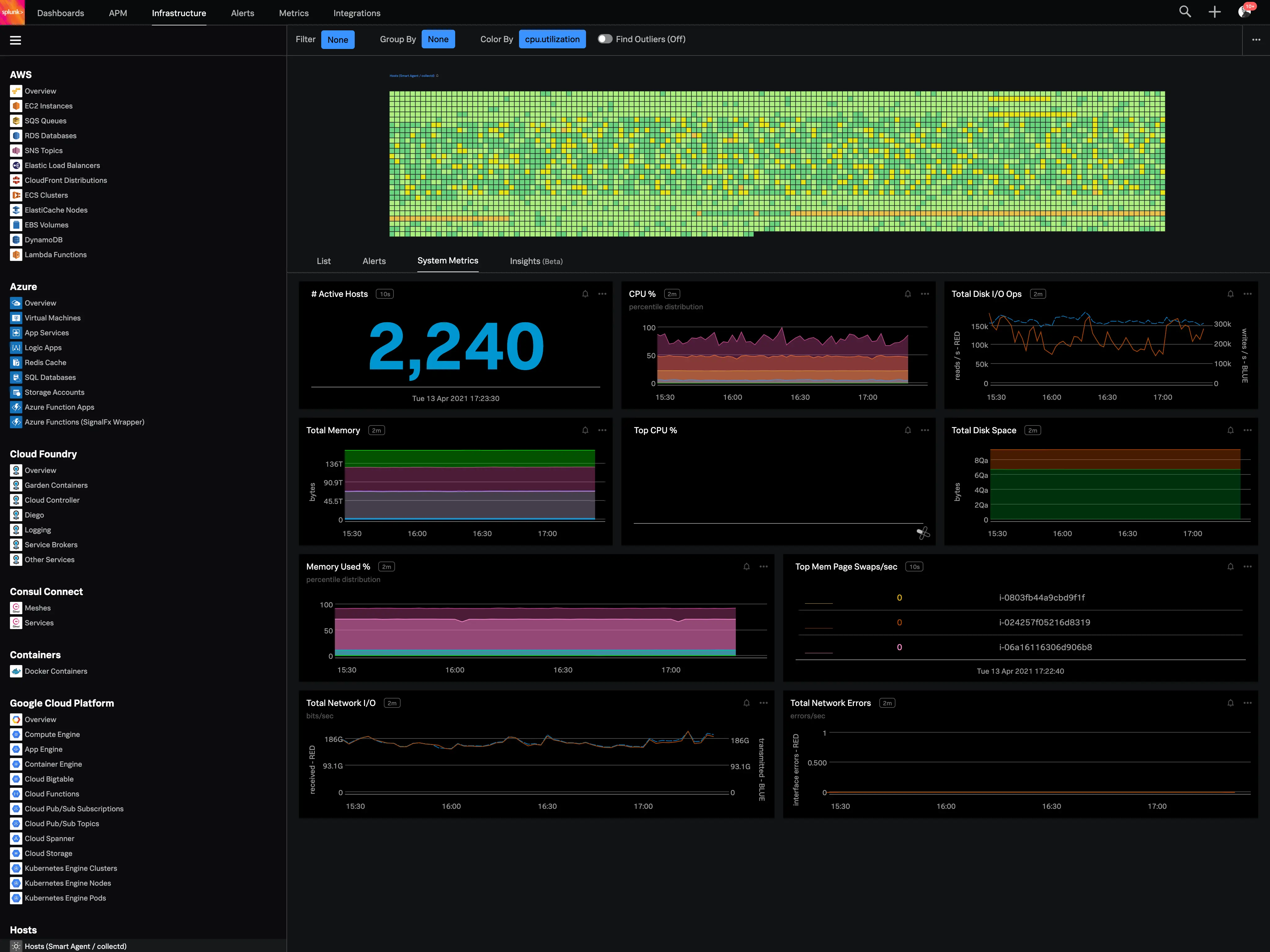
Splunk Observability Cloud combines real-time streaming metrics, APM, distributed tracing, and infrastructure monitoring with Splunk's established log analytics and SIEM capabilities. For large enterprises already using Splunk for security and compliance, extending into observability through Splunk Observability Cloud keeps telemetry within a familiar ecosystem.
Splunk's streaming metrics backend (originally SignalFx) provides real-time infrastructure and service performance monitoring with alert noise reduction that APM-focused teams find valuable. Integration with the broader Splunk platform means teams can correlate observability signals with security events, compliance logs, and audit trails without moving between separate systems.
For teams evaluating Splunk replacements, see our Splunk alternatives comparison.
Key features
- Real-time streaming metrics: High-resolution infrastructure and service metrics with built-in alert noise reduction
- APM and distributed tracing: Service performance monitoring with service maps and end-to-end trace analysis
- Log management and SIEM integration: Splunk's log analytics backbone connecting observability signals with security and compliance data
- AI-driven alerting: ML-based anomaly detection and alert correlation to reduce operational noise
- Enterprise ecosystem integration: Deep connectivity to Splunk Enterprise, Splunk Security, and SOAR workflows
Pricing
Splunk Observability Cloud uses custom enterprise pricing based on hosts, ingest volume, and modules. Standard rates are not publicly listed; pricing requires engagement with Splunk sales.
Pros
- Strong integration with Splunk's log analytics and security platform for organizations already using Splunk
- Real-time streaming metrics with built-in noise reduction for high-volume environments
- Mature enterprise features including governance, compliance, and audit capabilities
- Good service maps and APM for complex microservice environments
- Broad integration ecosystem within the Splunk and Cisco product portfolio
Cons
- High cost, particularly at large enterprise scale; custom pricing requires sales engagement
- SPL (Search Processing Language) has a significant learning curve compared to SQL-based querying
- Portfolio integration with the broader Cisco stack is still maturing into a seamless workflow
- Less effective for pure cloud-native teams without existing Splunk investment
- Pricing opacity makes cost modeling difficult before a formal sales engagement
Try Parseable, the enterprise-grade unified observability platform
6. Grafana Cloud
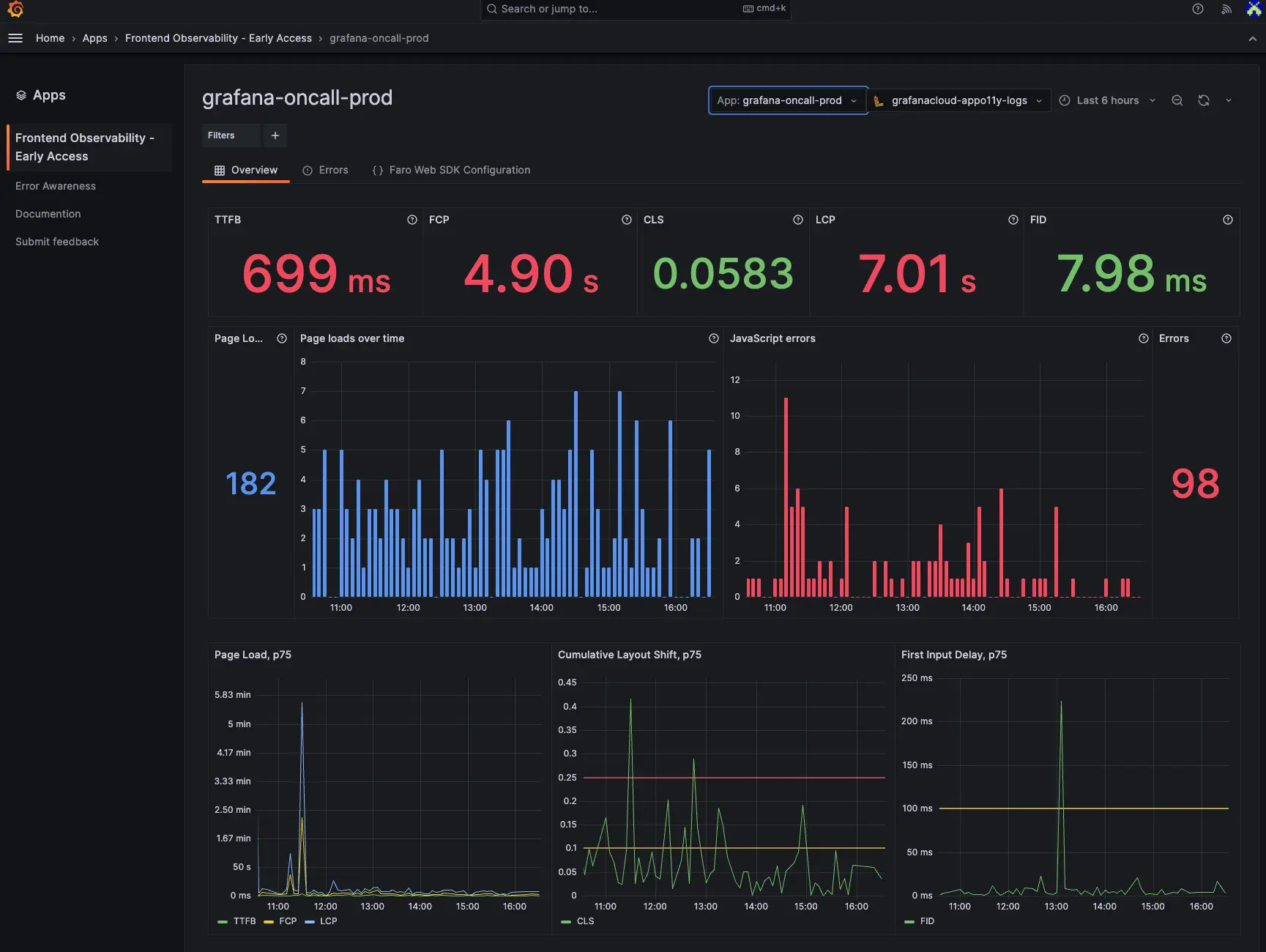
Grafana Cloud is the managed offering built on the open-source LGTM stack: Loki for logs, Grafana for visualization, Tempo for traces, and Mimir for metrics. For engineering organizations already running Prometheus and Grafana dashboards, or that require data portability and open-source alignment, Grafana Cloud provides a managed path without vendor lock-in on the underlying data formats.
Grafana dashboards are the de facto standard for metrics visualization in cloud-native environments. Loki keeps log indexing costs low by indexing only labels rather than full log content, which suits high-volume Kubernetes logging environments. Tempo and Mimir complete the observability stack with horizontal scalability on object storage.
Self-hosting the full LGTM stack gives teams complete control but carries operational overhead: each component scales independently and needs dedicated operational ownership. For teams that want the same architecture without that overhead, Grafana Cloud removes the burden while keeping data exportable.
Key features
- Grafana dashboards: Industry-standard visualization layer with an extensive plugin ecosystem and community templates
- Loki log aggregation: Label-based log indexing on object storage with significantly lower cost than full-text indexing
- Tempo distributed tracing: Open-source tracing backend with exemplar links from Prometheus and Mimir metrics
- Mimir for metrics: Horizontally scalable, Prometheus-compatible metrics backend with long retention on object storage
- OTel-native across the stack: Full OpenTelemetry collector compatibility for all LGTM components
- Grafana Cloud managed option: Removes self-hosted operational overhead while keeping data portable
Pricing
The open-source LGTM stack components are free to self-host under Apache and AGPL licenses. Grafana Cloud offers a free tier with generous limits for logs, metrics, traces, and dashboards. Paid tiers are usage-based and scale with ingestion volume, active series, and retention length.
Pros
- Open-source alignment with no proprietary data lock-in across logs, metrics, or traces
- Grafana dashboards are the industry standard for metrics visualization
- Loki's label-based indexing is cost-efficient for high-volume log environments
- Full OpenTelemetry compatibility across the entire stack
- Data exportability: teams can move to self-hosted or switch backends without losing telemetry
Cons
- Self-hosting the full LGTM stack is operationally intensive: multiple components to scale, tune, and maintain independently
- Grafana alone is a visualization layer; Loki, Tempo, and Mimir must be configured and operated alongside it
- Alert management (Grafana Alerting) is functional but less polished than purpose-built incident platforms
- No native AI assistant, incident management, or built-in RUM without third-party integration
- Grafana Cloud pricing at large ingest volumes requires careful modeling before commitment
7. Elastic Observability: Best for search-centric observability and ELK teams
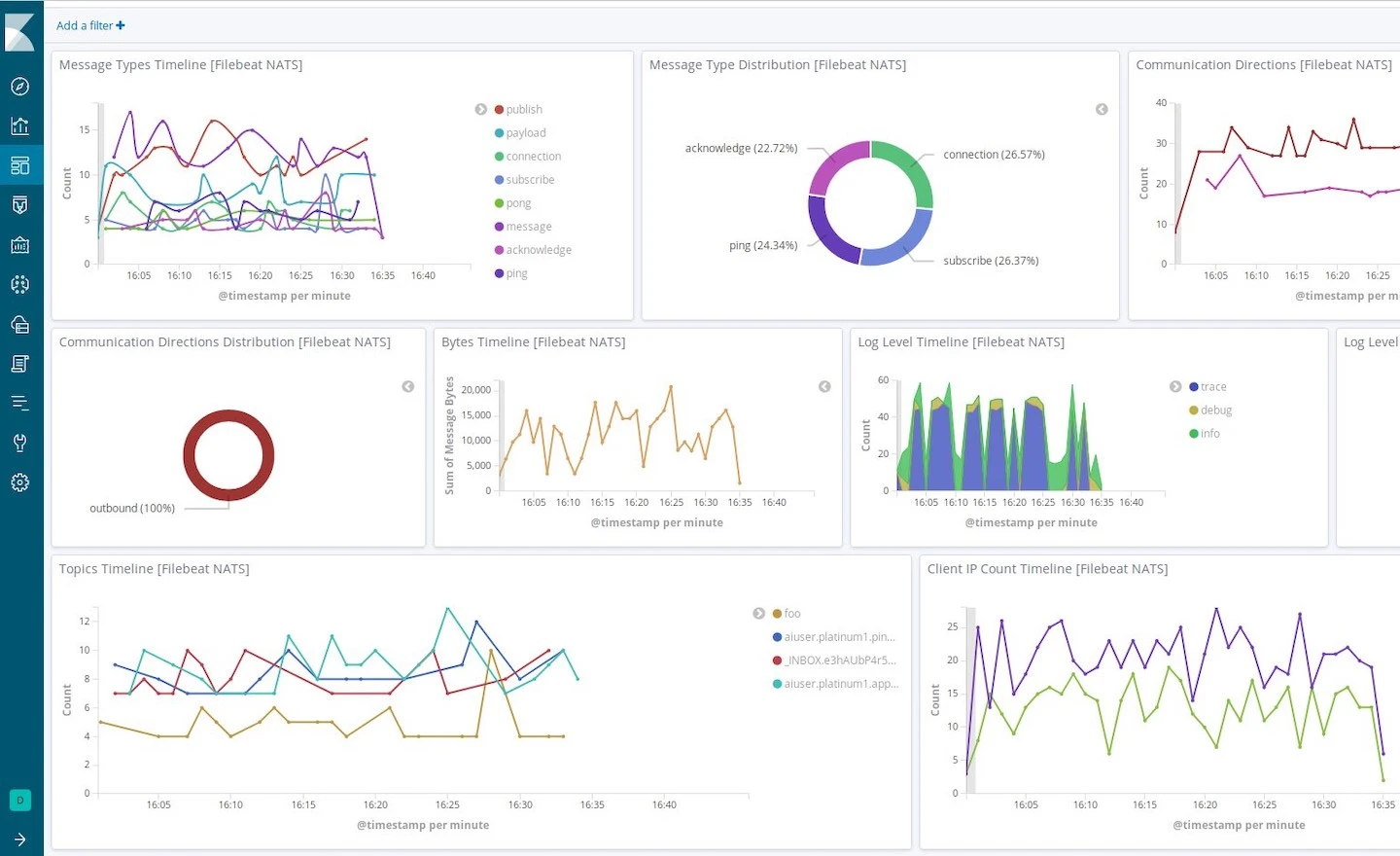
Elastic Observability is the enterprise observability layer built on Elasticsearch, Kibana, Beats, and Logstash. For teams with existing Elasticsearch infrastructure or deep ELK heritage, it is the natural extension into APM, distributed tracing, infrastructure monitoring, RUM, and uptime monitoring.
Kibana provides a unified investigation interface: from a dashboard anomaly, teams can pivot to raw log search, APM traces, and infrastructure metrics without switching tools. Elasticsearch's full-text search engine makes Elastic Observability particularly strong for teams that need deep, unstructured log querying across large datasets.
ML jobs can auto-detect anomalies in metrics and log patterns, and Elastic Security's SIEM capabilities can share the same cluster as observability data, which reduces infrastructure overhead for teams that need both security and operational observability.
Key features
- Elasticsearch full-text search: Industry-leading log search with inverted-index querying across large unstructured datasets
- Kibana unified interface: APM, logs, metrics, uptime, and RUM accessible from a single UI with cross-signal pivot
- APM agents for 10+ languages: Auto-instrumentation-friendly agents with distributed trace correlation
- ML anomaly detection: Automatic anomaly detection on metrics and log patterns through built-in ML jobs
- Elastic Security and SIEM: Security analytics that shares the same cluster as observability data
- Flexible deployment: Self-hosted open-source, Elastic Cloud managed, or hybrid
Pricing
The Elasticsearch engine and core stack components are available as open source. Elastic Cloud managed deployments start from approximately $95/month and scale with cluster size, storage, and feature tier. Enterprise and security features require higher-tier subscriptions.
Pros
- Full-text search depth that no other observability platform matches for unstructured log querying
- Self-hosted option with full data control for compliance-driven environments
- Kibana is a mature, full-featured dashboard and analytics layer
- ML anomaly detection is built in without separate add-on pricing
Cons
- Index and shard management at scale requires significant Elasticsearch expertise
- Storage costs grow quickly with long retention due to inverted-index overhead
- Operational complexity is substantially higher than SaaS alternatives for self-hosted deployments
- APM and distributed tracing, while solid, lack the automated service mapping depth of Dynatrace or Datadog
- Index mapping explosions from high-cardinality telemetry are a common operational risk without careful design
Ready to see Parseable in action with your own data? Book a discovery call.
8. Chronosphere: Best for metrics-heavy Kubernetes and high-cardinality environments
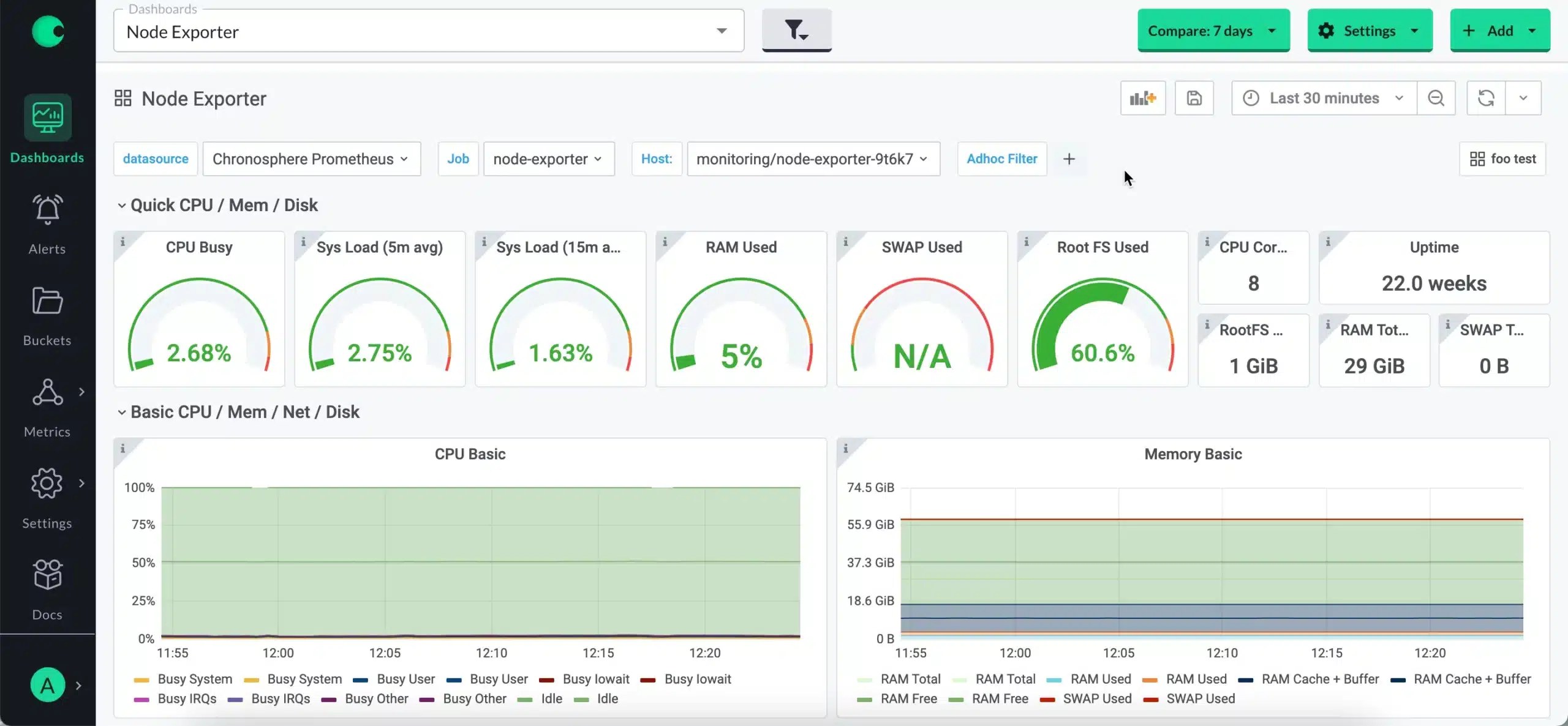
Chronosphere was built by engineers who scaled metrics infrastructure at Uber, and the platform reflects that background. It is designed for organizations with very large Kubernetes estates, millions of unique metric time series, and Prometheus-scale cost control challenges. Its Control Plane approach treats observability as a cost and governance problem first, which is a meaningful differentiation for platform teams managing shared observability infrastructure across multiple product teams.
Chronosphere's M3-based metrics backend handles high-cardinality metrics with smart aggregation, rollups, and retention policies that prevent cardinality explosions. PromQL compatibility means teams can migrate from Prometheus, Thanos, or Cortex without rewriting alert rules or dashboards.
Key features
- Observability Control Plane: Team-level quotas, cost attribution, and cardinality budgets for shared platform environments
- M3-based metrics backend: Handles billions of unique time series with aggregation, rollup, and retention policies
- PromQL compatibility: Migrate from Prometheus, Thanos, or Cortex without rewriting queries or alert rules
- SLO and dependency management: Built-in SLI/SLO tracking with service dependency mapping for blast-radius analysis
- Lens distributed tracing: Service-to-service trace correlation alongside the metrics-first core
- Log support: Growing log management capabilities integrated with the metrics platform
Pricing
Chronosphere uses custom enterprise pricing tailored to metrics scale and team size. Pricing requires direct engagement with Chronosphere sales. It is best suited for large Kubernetes environments where the cost governance capabilities justify the investment.
Pros
- Best-in-class cardinality control and cost governance for metrics-heavy Kubernetes environments
- PromQL compatibility enables migration from Prometheus without rewriting queries
- Team-level quota and cost attribution for shared observability platform management
- SLO management is a first-class feature, not a bolt-on
- Purpose-built by engineers who have operated at extreme metrics scale
Cons
- Primarily a metrics-first platform; log and trace maturity is still growing relative to dedicated APM tools
- Custom enterprise pricing is not accessible to smaller or mid-size teams
- UI is engineering-focused and pragmatic; less visually polished than Datadog or Honeycomb for application developers
- Overkill for teams without genuine high-cardinality metrics challenges
9. Coralogix
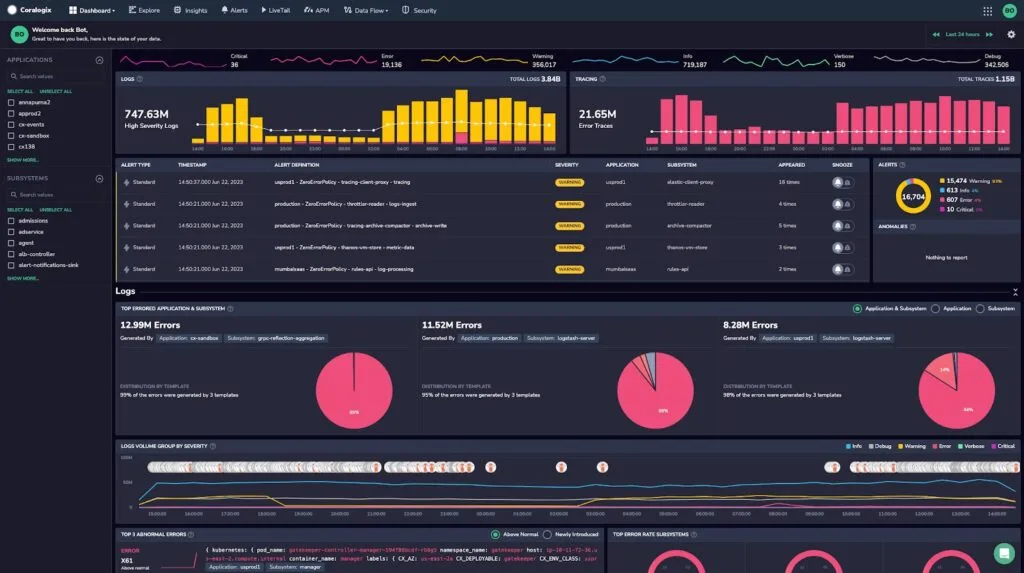
Coralogix uses a streaming analytics architecture that processes telemetry data in-flight before it lands in storage. This allows real-time alerts and anomaly detection without indexing all data, which is a significant cost and operational advantage for teams with high log volumes and diverse cardinality requirements.
The TCO Optimizer automatically classifies logs into three tiers: frequent search (fully indexed for interactive query), monitoring (aggregated to derived metrics only), and compliance (archive only). This automated tiering can reduce indexing costs by 70 to 80 percent while keeping critical data accessible. The Loggregation feature condenses repetitive log events into representative metrics, further reducing storage overhead for verbose applications.
Key features
- Streaming analytics architecture: Process logs, metrics, and traces in-flight for real-time detection without indexing everything
- TCO Optimizer: Automated log tiering into frequent search, monitoring, and compliance tiers to reduce indexing cost
- Loggregation: Turns high-volume repetitive log events into derived metrics, reducing storage overhead
- AI incident assistant: Alert clustering, anomaly detection, and root-cause suggestions across log and metric signals
- OpenTelemetry and Prometheus support: OTel-native ingestion with native Grafana integration for dashboards
- Version benchmarking: Compare telemetry before and after deployments to detect regressions automatically
Pricing
Coralogix uses usage-based pricing. Enterprise pricing requires contacting Coralogix sales. The TCO Optimizer can significantly reduce effective cost by diverting low-value log volume away from indexed tiers.
Pros
- Streaming analytics architecture enables real-time detection without indexing all data
- TCO Optimizer can dramatically reduce log storage costs for verbose, high-volume applications
- Loggregation converts repetitive log noise into derived metrics, reducing both cost and alert fatigue
- Strong OTel and Prometheus support with native Grafana dashboard integration
- Version benchmarking for automatic deployment regression detection
Cons
- Cross-signal correlation (from a metric spike to related traces to specific log lines) is less seamless than APM-first platforms; validate in a POC before committing
- UI and alerting workflows are functional but less polished than Datadog or New Relic for teams expecting a consumer-grade experience
- RUM and session replay are newer; validate against frontend observability requirements
- Pricing requires sales engagement for enterprise volumes; not fully transparent upfront
10. Honeycomb
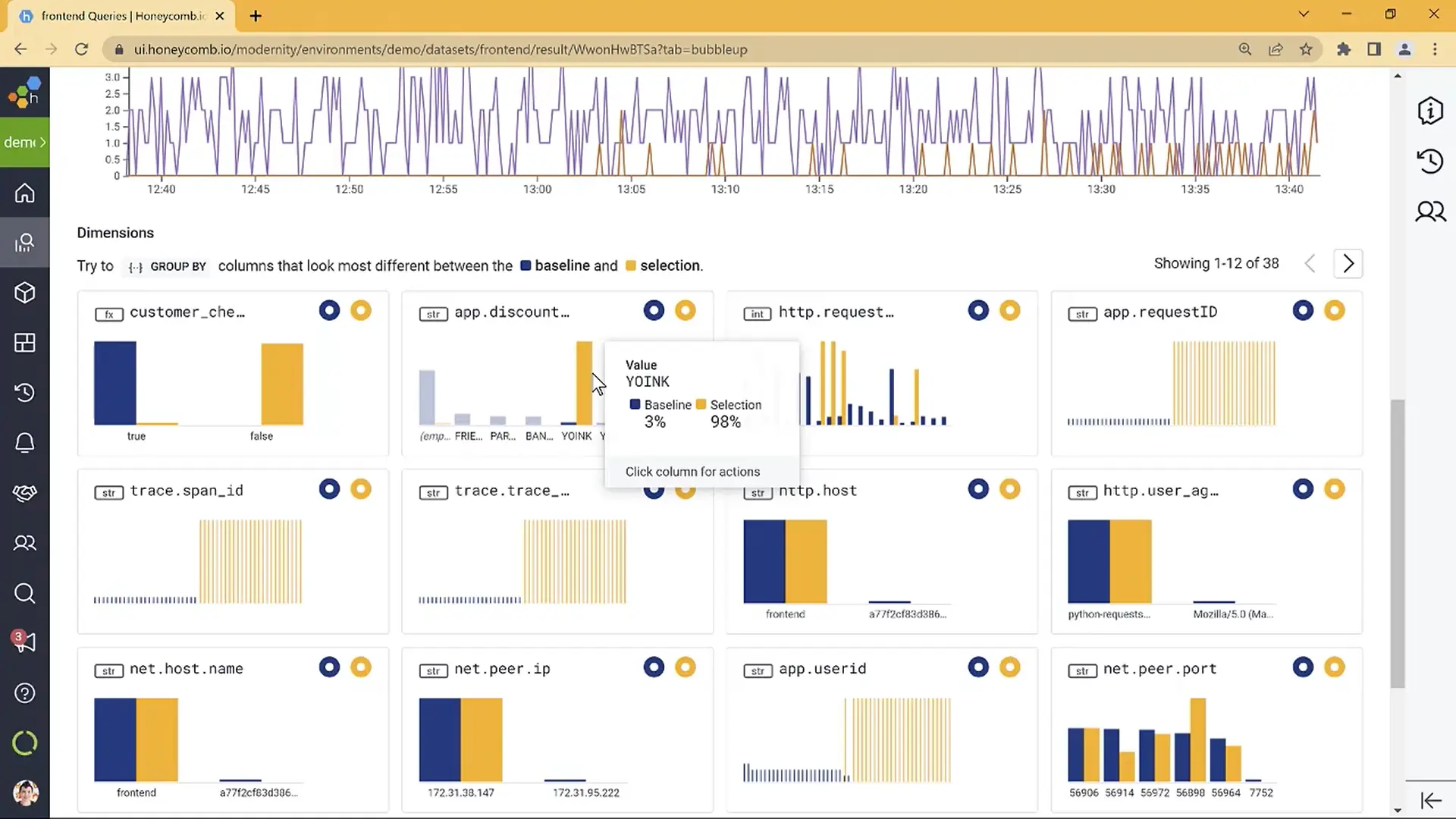
Honeycomb is an observability platform built around high-cardinality event analysis for distributed system debugging. It stores wide, structured events rather than traditional log lines or metric series, and provides a query experience designed to help engineers rapidly identify patterns, outliers, and root causes across complex microservice architectures.
Honeycomb is particularly strong for application engineering teams that need to debug subtle, hard-to-reproduce issues by exploring millions of events across arbitrary fields and dimensions. Its BubbleUp investigation feature surfaces statistical anomalies in event properties that correlate with degraded performance, reducing the exploratory work that normally falls on senior engineers during active incidents.
Key features
- High-cardinality event analysis: Store and query wide structured events with arbitrary fields, enabling investigation across dimensions that traditional tools drop due to cardinality limits
- Distributed tracing: End-to-end trace analysis with service maps and dependency visualization
- BubbleUp investigation: Statistical anomaly surfacing across event properties to identify correlated factors during performance degradation
- Query Assistant: AI-assisted query construction for teams new to the Honeycomb query model
- SLOs: Service level objective tracking and error budget management
- OpenTelemetry support: Native OTLP ingestion for events, logs, and traces
Pricing
Honeycomb offers a free tier with 20 million events per month and 30-day retention. The Team plan starts from $100/month. Enterprise pricing is custom.
Pros
- Best-in-class high-cardinality event analysis for complex distributed system debugging
- BubbleUp makes statistical anomaly investigation accessible without expert query construction
- Query model is flexible and optimized for exploration during active incidents
- OpenTelemetry-native ingestion supports vendor-neutral telemetry pipelines
- Strong fit for engineering-led teams investigating complex microservice behavior
Cons
- Not a full-stack observability platform: infrastructure monitoring, RUM, synthetics, and security analytics require separate tools
- The event-centric query model has a learning curve for teams used to dashboard-first workflows
- Less suited for operations-heavy teams that primarily need metrics monitoring and log aggregation
- Enterprise pricing requires sales engagement and is not transparent at scale
- Smaller integration ecosystem than broader enterprise platforms
Cost engineering: keeping observability affordable at enterprise scale
Observability does not have to become a blank check. Engineering cost controls into the design from the start prevents the budget surprises that hit teams 6 to 12 months after a platform adoption.
- Right-size retention by domain: 7 to 14 days hot for production application logs; longer for compliance and audit streams in warm or cold tiers.
- Use intelligent sampling: Keep 100 percent of traces for error and latency outliers; sample aggressively for healthy-path traffic.
- Adopt hot/warm/cold architecture on object storage: Keep recent data in fast query tiers and age to S3-class storage while keeping it queryable on demand.
- Define query budgets per team: Alerts on query volume and cost, with automated guidance to reduce expensive full-table scans.
- Normalize noisy logs at the edge: Use OTel processors to drop low-value noise or tokenize repetitive payloads before they reach the platform.
Platforms built on object storage with columnar formats, including Parseable, allow teams to keep more data online for less cost without moving older telemetry into unqueryable archives. That changes the economics of long-retention observability for compliance and forensic use cases.
Why Parseable is a strong starting point for enterprise observability
For teams building or rebuilding an observability stack, Parseable addresses the three constraints that most often derail enterprise observability projects: cost at scale, query accessibility, and deployment flexibility.
- OpenTelemetry-native from day one: Bring existing collectors and exporters without proprietary agents or format conversions
- SQL-first exploration: Engineers already know SQL; that means faster investigation, clearer hypotheses, and reusable queries across teams
- Object-storage economics: Keep more data online longer without moving telemetry to inaccessible cold archives
- AI with evidence links: Anomaly detection, incident summaries, and next-step suggestions linked to specific queries, log lines, and traces
- Full deployment flexibility: Self-hosted, Parseable Cloud, and BYOC for compliance-driven and cost-sensitive environments
Try Parseable for free with your own data and see why it's the best enterprise observability platform.
AI in observability: useful today, still developing
Where AI helps now
- Noise reduction and triage: Grouping alerts by underlying signal and symptom rather than raw threshold counts
- Incident summaries: Turning a noisy incident timeline into a structured narrative with the likely cause, affected services, and suggested next steps
- Query coaching: Translating questions like "why did p95 latency double?" into the right log, trace, and metric queries with linked evidence
- Forecasting: Anticipating saturation in ingest pipelines, CPU headroom, or memory before it generates an incident
Where AI still requires scrutiny
- Explainability: SREs need to see why a suggestion was generated, through topology context, change events, and dependency data, not just the conclusion
- Privacy and governance: AI summaries need RBAC-aware scope and PII scrubbing, particularly in multi-tenant or regulated environments
- Actionability over novelty: AI that links to verifiable evidence and triggers runnable remediation actions is more useful during incidents than AI that narrates without supporting data
Common pitfalls to avoid when evaluating observability platforms
- "Single pane of glass" without connected workflows: Dashboards that surface all signals simultaneously are table stakes. The real value is how quickly a team can connect a red graph to a specific deployment, configuration change, or dependency failure.
- Ignoring data lifecycle costs: If all telemetry stays in hot storage indefinitely, the bill grows unpredictably. Tier aggressively from the start with defined SLAs on retrieval time and cost per tier.
- Underestimating cardinality costs: Labels and tags are easy to add and expensive to index at scale. Budget cardinality like you budget CPU or memory.
- Skipping governance during evaluation: RBAC, audit logs, and data boundary controls matter, particularly when AI is part of the investigation workflow and when regulatory requirements apply.
- Self-hosting without clear ownership: Self-hosted platforms can deliver better economics but only when a team owns upgrades, performance tuning, and platform-level incident response as dedicated responsibilities.
Conclusion
Enterprise observability platforms in 2026 need to do more than store telemetry. They need to help teams understand why things break, not just that something broke. The strongest platforms correlate signals across logs, metrics, traces, and topology; support OpenTelemetry-native pipelines; control cost at scale through architecture rather than aggressive data discarding; and provide governance features that meet enterprise compliance requirements.
For teams starting a fresh evaluation, Parseable is the strongest starting point for cost-efficient unified observability. Its object-storage architecture, SQL-first querying, OpenTelemetry-native ingestion, and flexible deployment give engineering organizations a platform built for scale without the lock-in and cost curve of legacy incumbents.
For teams already running Datadog, Dynatrace, or Splunk, the decision to switch or augment depends on whether the current platform's cost, query model, or deployment constraints have become a limiting factor. For teams building new observability stacks on Kubernetes with Prometheus and Grafana, Grafana Cloud and Parseable both provide strong open-source-aligned options with full data portability.
Try Parseable for free and run the evaluation on your own workloads.
FAQ
What are the best enterprise observability platforms in 2026?
The best enterprise observability platforms in 2026 include Parseable, Datadog, Dynatrace, New Relic, Splunk Observability Cloud, Grafana Cloud, Elastic Observability, Chronosphere, Coralogix, and Honeycomb. Parseable stands out for teams that need cost-efficient unified telemetry, OpenTelemetry-native ingestion, SQL-based querying, and flexible deployment including self-hosted and BYOC configurations. The right choice for any organization depends on signal requirements, scale, budget, deployment model, and existing stack context.
What is the difference between observability tools and observability platforms?
Observability tools typically address one layer: a metrics store, a log aggregator, a tracing backend, a dashboarding layer, or an APM agent. Many teams run several of these together. Enterprise observability platforms unify multiple telemetry signals into a single data model, investigation workflow, and governance layer. The value of observability comes from correlation across signals during incident investigation, not from any individual signal store in isolation.
What should enterprises look for in an observability platform?
The most important evaluation criteria are: comprehensive signal coverage (logs, metrics, traces, events, RUM), OpenTelemetry support for vendor-neutral pipelines, cross-signal correlation for efficient incident investigation, cost controls at scale (storage architecture, retention tiers, sampling strategies), AI-assisted investigation capabilities, governance features (RBAC, SSO, audit logging, data residency), and genuine deployment flexibility (SaaS, self-hosted, BYOC). Teams should model cost at 2x and 10x current ingest volume before finalizing any decision.
Why is OpenTelemetry important for enterprise observability?
OpenTelemetry provides a vendor-neutral standard for collecting logs, metrics, and traces across applications, infrastructure, and services. Adopting OTel as the ingestion layer reduces lock-in to any specific observability platform and keeps telemetry pipelines portable as your architecture evolves. For enterprise teams managing dozens of services across multiple engineering teams, OTel-native platforms reduce ongoing instrumentation overhead compared to proprietary agent ecosystems. It also preserves optionality: teams can augment or replace backend platforms without re-instrumenting services.
Which enterprise observability platform is best for cost control?
Parseable offers the strongest cost control at scale through its object-storage-first architecture, columnar storage with Apache Parquet, and ingestion-based pricing at $0.39/GB with 365-day retention. Grafana Cloud and Grafana Loki also provide cost-efficient log storage through label-based indexing on object storage. Coralogix's TCO Optimizer and tiered storage can significantly reduce effective log storage costs for verbose, high-volume applications. Teams should compare total cost at their actual ingest volume and retention requirements, not just the base per-GB rate.