




Generative AI has been making waves recently, and we're excited to announce how we've used OpenAI to bring Natural Language-based SQL generation to Parseable. In this blog post, we'll delve into the technical aspects of this feature, its potential applications, and what lies ahead on our development roadmap.
With release version 0.7.0, Parseable introduces a nifty little feature for querying your log data: the ability to write in natural language and automatically generate SQL queries from it.
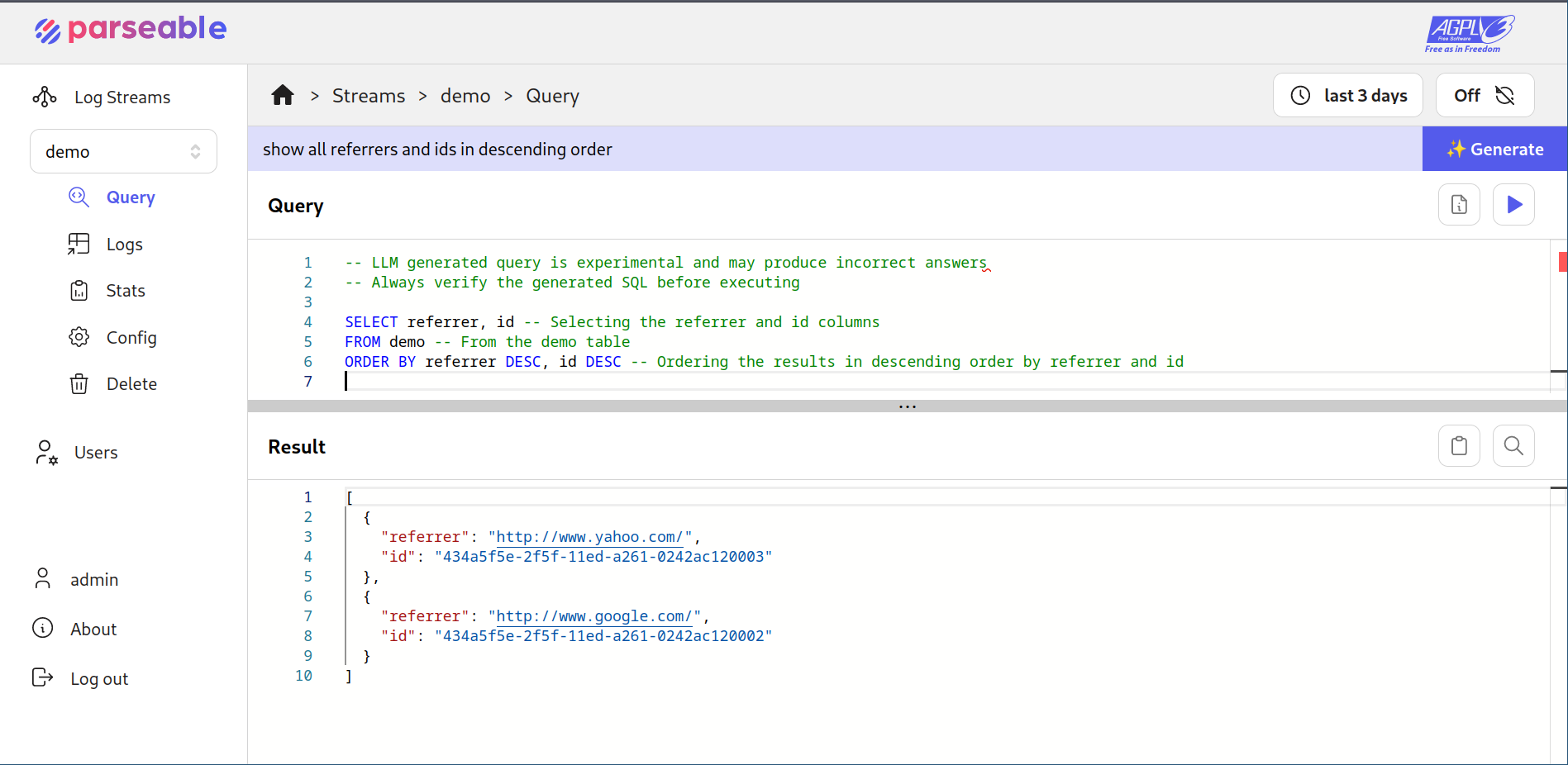
Our motivation behind this new feature was to make Parseable more accessible to users, regardless of their technical background or familiarity with SQL. Previously, users could retrieve logs based on time duration and write SQL queries to query the database. Now, with Natural Language Querying, the process becomes even more user-friendly and intuitive.
How It Works
Let's dive into how this feature works and it's architecture:
The Process
Configuration: Users or organizations can enable the Natural Language to SQL generation feature by adding their OpenAI API key to the backend environment variables.
User Interface: Once the API key is detected by the server, a new input box for natural query automatically appears in the user interface for Query tab.
Contextual Information: To provide context for the prompt, the table name and schema (including column names and data types) are passed to the Large Language Model (LLM).
Natural Language Input: Users can enter natural language queries (eg:"show all referrers in descending order") This input is then converted into valid SQL syntax (eg: "select referrer from demo order by p_timestamp desc.")
Validation and Execution: Users can inspect and validate the generated SQL before executing the query to obtain results.
Under the Hood: Architecture
The architecture of the Natural Language Querying feature involves several key components:
Backend Integration: The LLM API key and prompt are securely stored in the backend.
Frontend User Interface: Users interact with a user-friendly input field to enter natural language text.
Data Retrieval: The frontend sends the user's input and the associated stream name to the backend.
Contextual Information: The backend fetches column names and data types from the schema, stringify them, and include them as part of the prompt for the LLM.
Query Generation: The LLM processes the input, schema, and prompt to generate SQL, which is then sent back to the client application.
User Validation: Users have the option to review and validate the generated SQL before executing the query to retrieve results.
Status Indication: The backend provides an API endpoint ("/about") that the frontend can use to check the status of the LLM activation and ensure that the API key is properly configured on the server.
Technical Considerations
Client-side vs. Server-side OpenAI Requests
We opted for server-side requests to provide a unified API for potential future LLM integrations.
This approach allows for enhanced authentication and usage restrictions.
Ensuring the OpenAI key remains secure and avoiding potential cross-site scripting attacks were key reasons for this choice.
Crafting an Effective Prompt
Generating SQL-specific prompts for the LLM while keeping token size minimal posed a challenge.
We designed a prompt that conveys the necessary information while maintaining a small footprint:
fn build_prompt(stream: &str, prompt: &str, schema_json: &str) -> String { format!( r#"I have a table called {}. It has the columns:\n{} Based on this schema, generate valid SQL for the query: "{}" Generate only simple SQL as output. Also add comments in SQL syntax to explain your actions. Don't output anything else. If it is not possible to generate valid SQL, output an SQL comment saying so."#, stream, schema_json, prompt ) }
Providing Context to the LLM
- To ensure meaningful output, we pass the column names and data types from the schema to the LLM. This approach balances effectiveness with privacy concerns.
Temperature Value
- We experimented with temperature values and found that a value of 0.7 aligns well with our instructions. Further adjustments can be made as needed.
Encouraging User Validation
- In the frontend, once the response is received, we include a message prompting users to double-check the SQL. Given Parseable's SQL editor limitations (allowing only select actions), this additional precaution enhances user safety.
Future Plans and Roadmap
For Parseable, we have exciting plans for the future:
Anomaly Detection Alerts: We have plans to introduce anomaly detection algorithms that lears on log data and provide alerts when anomalous or strange behaviour appears in your data to enhance log analysis.
Support for More LLMs: In addition to OpenAI, we'll explore support for other Large Language Models and self-hostable LLMs.
Conversation Retrieval Chains: We're considering using Natural Language to modify generated SQL further, opening up new possibilities and even complicated queries for users.
Advanced AI Queries: We may leverage Generative AI to ask complex questions directly about log data, in a chat based format, making Parseable even more versatile.
Conclusion and Afterthoughts
At Parseable, our mission is to simplify log analytics and make it accessible to all. These new features are a significant step in that direction. As an open-source project, we thrive on adaptability and welcome contributions to expand this space further!
Credits and Inspiration
Share Your Feedback and Suggestions
Do try out this cool new feature in Parseable. If you have any comments or feedbacks, do join our Slack channel, and let's start a conversation!